Summarizing Youtube Comments with Machine Learning
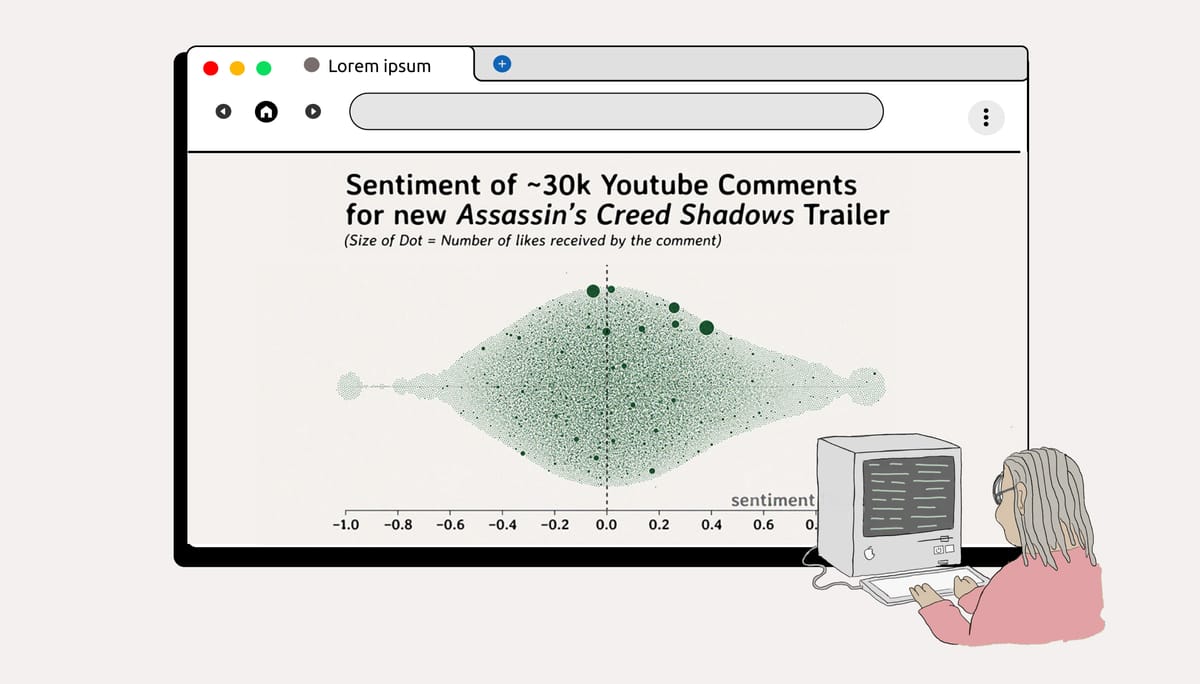
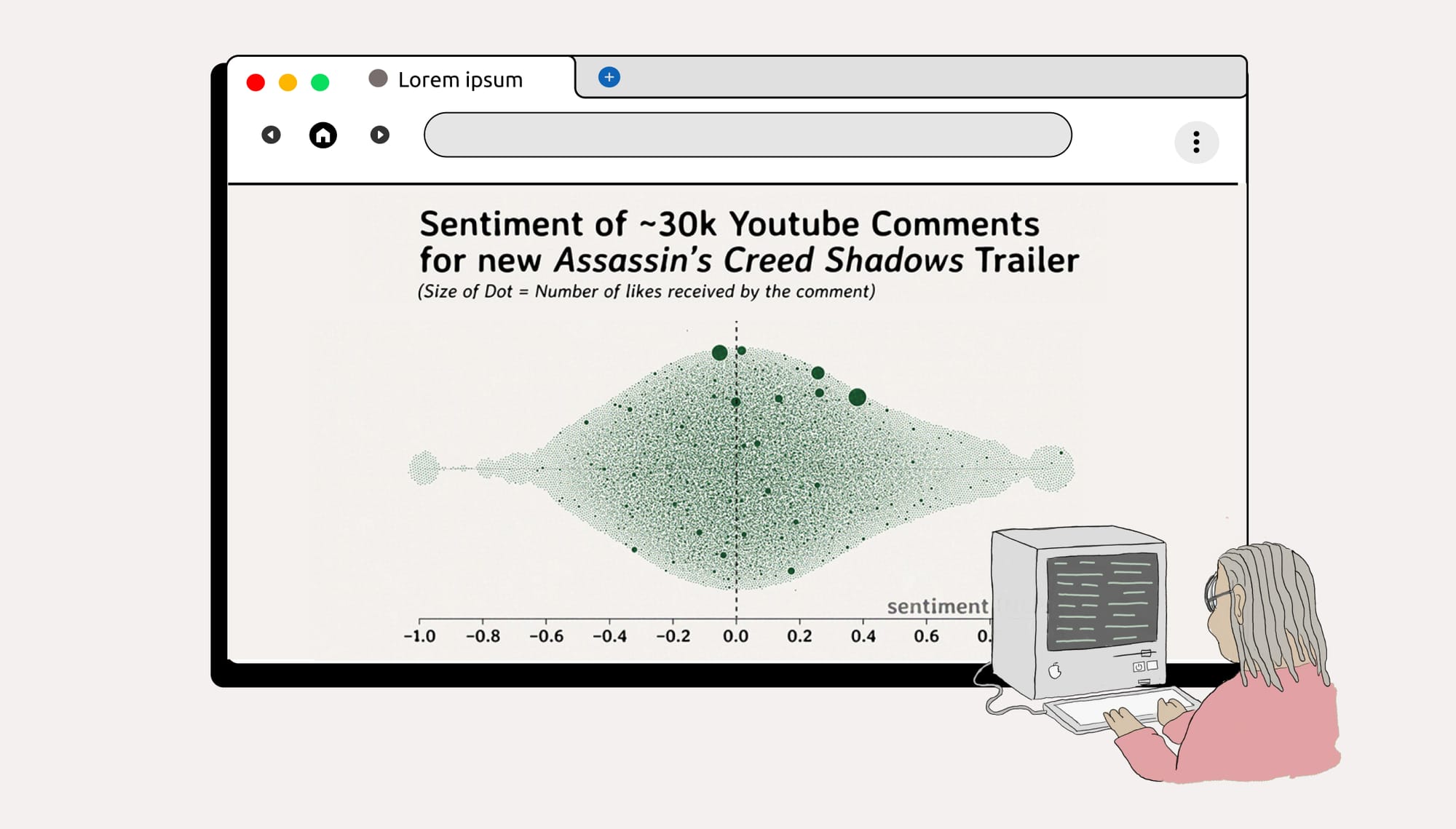
This tutorial will cover a few different techniques to accomplish a simple task: figuring out what people in the comments are saying about a video.
To summarize, the process will go like this:
- we will choose a video and scrape the comments using Youtube's API
- we will tokenize (aka simplify) the comments so it's easier for the algorithms to process (I'll compare and contrast different methods)
- we will analyze the tokenized comments to see which topics people are talking about, and how they feel about those topics
I have a separate tutorial that will focus on the sentiment of the Youtube comments once we have our topics, but everything in due time.
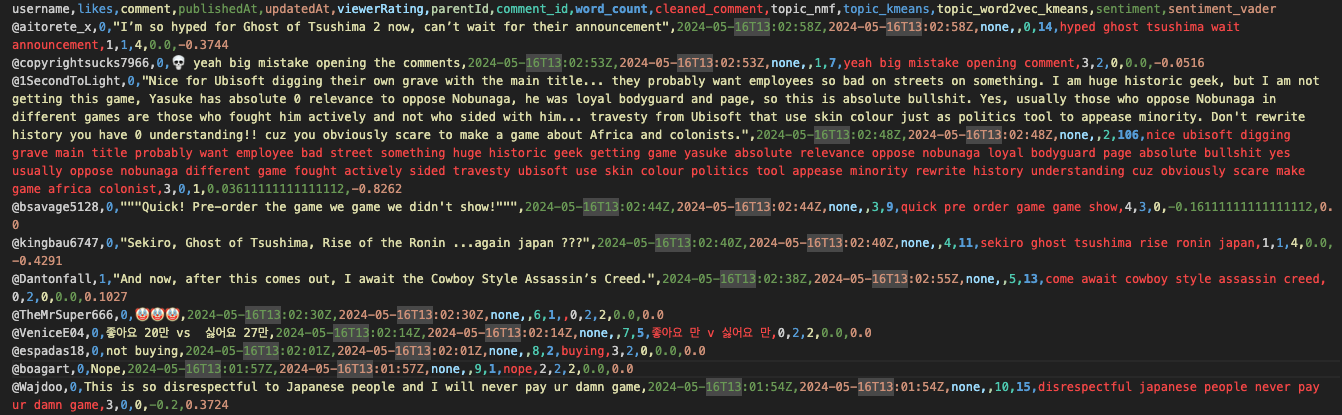
The end result of this should be a csv with a list of the comments, their original form, their tokenized form, an assigned topic, and a sentiment score (and some other furniture. Here's a look at the end result.
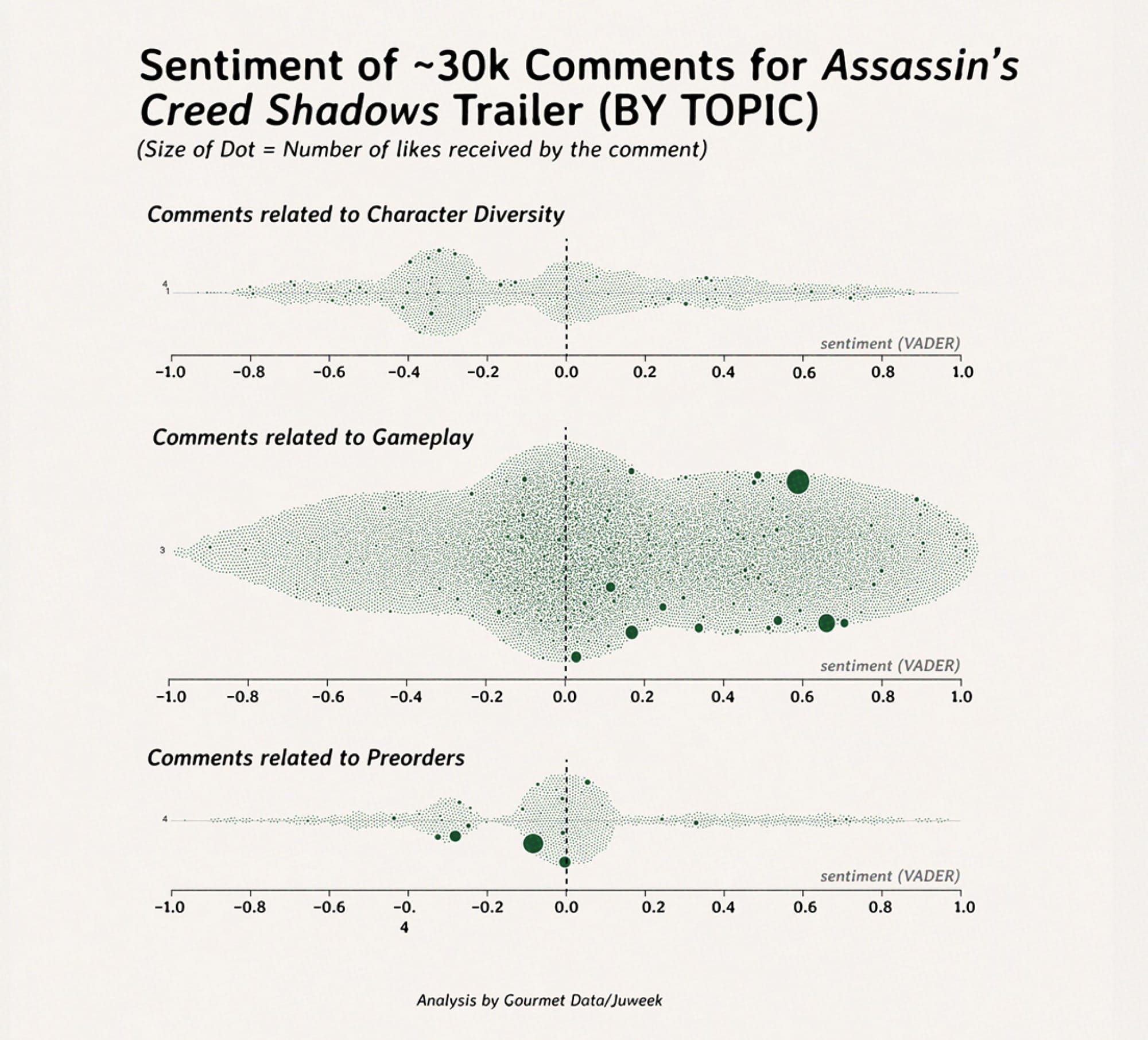
And, because of those comments, I can make a graph like this, where I separate the comments into topics, and assign each a sentiment score.
While I can't share the whole creation process, here's the script for sale if you want to insert a video and get the screenshot output.
Scraping the Youtube Video Comments
In order for this to be worth either of our time, it's important to choose a video that you can actually gain insight from. Only advice I can give now is to choose one with over 1k comments (the more the better), and interviews work well.
1) Get Access to the YouTube Data API
- This involves creating a Google Cloud account, and new project, which can be done on the Google Cloud console page.
- In your project dashboard, navigate to the "APIs & Services" section, search for the YouTube Data API, and enable it.
- Create API credentials (API key) for accessing the API. This key will be used to communicate to Youtube's API.
2) Install Required Libraries
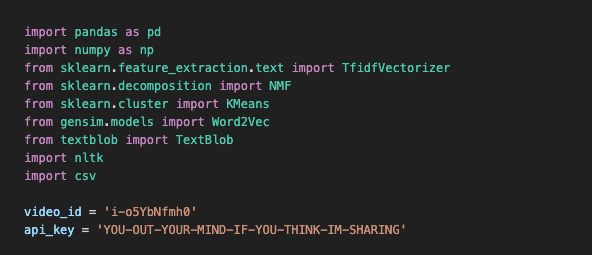
You will need the google-api-python-client library to interact with the API. You can install it using pip. NLTK, pandas, and scikit-learn are three specific and very common examples; I would start with those.
The below is a screenshot of some of the imports you'll need to install in the beginning; Python's strengths come from the fact that there are some really powerful libraries out there for data science, and I'll tell you a secret; you can get quite far with looking up the right algorithm and passing it through the right csv. That's a good 50% of my job.
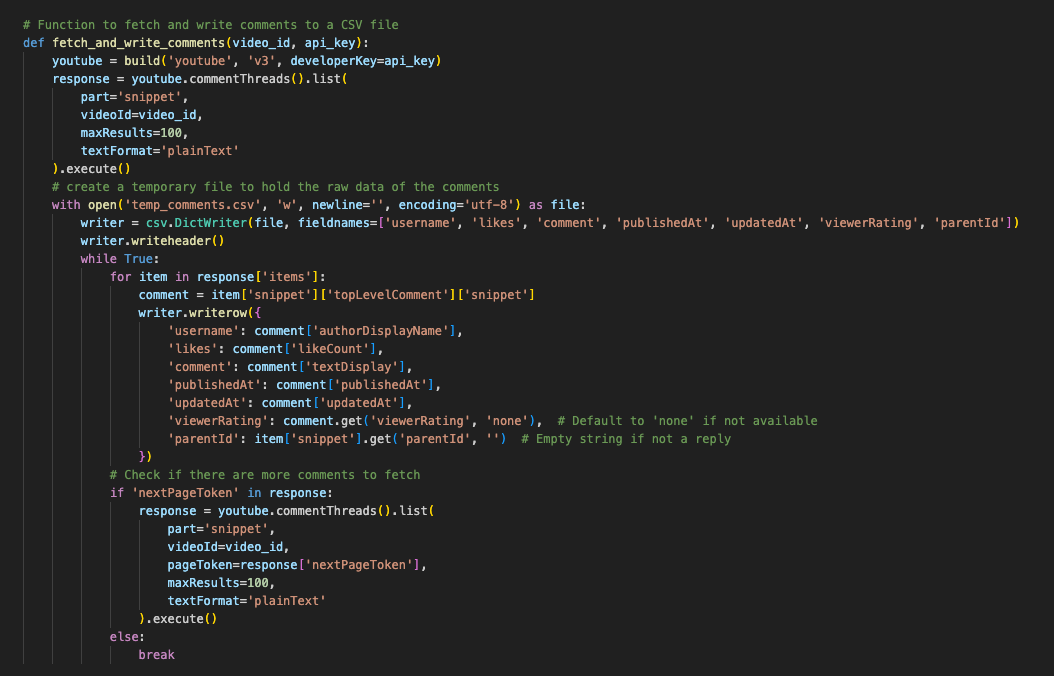
3) Write the Python function
Here's the rest of the code; I pass in the video id and the api key, and essentially run youtube's api by executing the youtube.commentThreads().list() function, and writing the response to a csv.
Cleaning the Text
If 50% of my job is sic-ing data science algorithms at csv, the other 50% is cleaning up text.
The concept of tokenizing is simple; computers and algorithms do better when they get closer to binaries, and numbers are closer to binary systems than letters.
In the realm of text analysis, there is also something to be said about the usage of stop words (um, the, a, etc). Let's get that bullshit outta here.

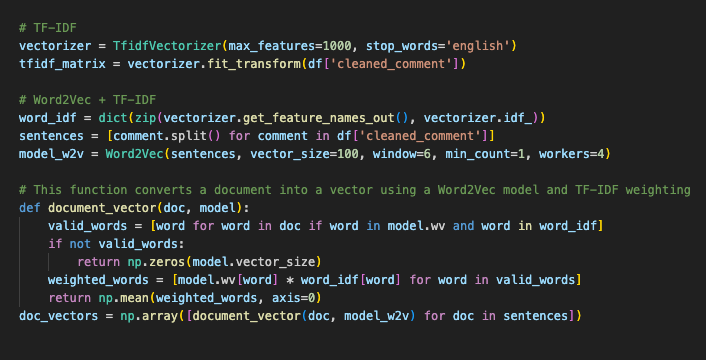
There are actually two ways to vectorize text that I use; TF-IDF and Word2Vec.
- TF-IDF (Term Frequency-Inverse Document Frequency) transforms text into numerical values by measuring how important a word is in a document relative to a collection of documents; it gives more weight to unique words in a document.
- Word2Vec creates numerical vectors for words based on their context in a text. It captures the semantic meaning by considering the words surrounding each target word, representing the relationships between words.
The purpose of me showing both of these algorithms is to give you a look into how many options there are; different algorithms are tailored for different things, and analyzing data using these charts is not an exact science; rather, it's used to 'summarize'.
Figuring Out Which Topics People Are Talking About
The next thing on our list is something called topic modeling; essentially, this is a situation in which we try to group the comments by topic, and just like there are a few ways to tokenize text, there are a few ways to topic model: NMF and KMeans. each algorithm comes out with a similar output; a grouping of X amount of words that seem to be related to each other. This, in essense, is your 'topic'. (This is an example for a Mark Zukcerberg interview with Dwarkesh.)

TF-IDF + NMF: To start, TF-IDF combined with NMF is a solid choice. This method highlights unique words in your documents, and NMF helps by identifying patterns in word usage. It's great when you need to understand the underlying structure of your text, especially if you're working with comments that have clear, separate topics.
TF-IDF + KMeans: You can also use TF-IDF with KMeans clustering. This combo transforms text into numerical values and, K-Means groups similar values together. It’s particularly useful when you have a large dataset and need a quick way to categorize it, such as organizing reviews or responses into thematic clusters.
Word2Vec + KMeans with TF-IDF Weighting: If you’re dealing with more complex text where the context and relationships between words are crucial, I ended up using Word2Vec with KMeans and TF-IDF weighting. Word2Vec captures the meaning of words based on their context, and TF-IDF weights them by importance. This method is ideal for applications like sentiment analysis, which we plan on doing further down.
Below is the code where I write each of the methods; you can see how, in actuality, reach set of algorithms take only a few lines of code. Isn't Python awesome?
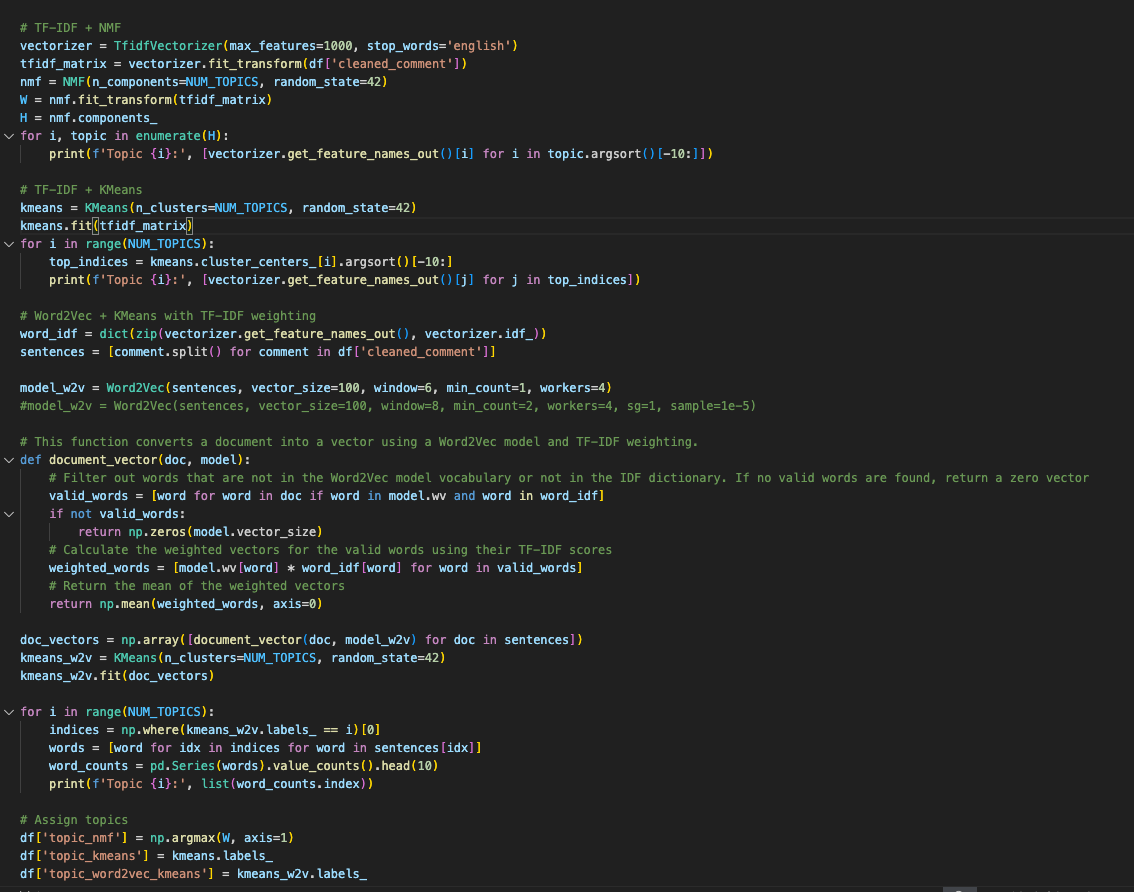
The last few lines are me adding the topics to the original dataframe holding the csv. Creating this new dataframe is essential for any visualization we might want to create, because we need a numerical metric to chart on a graph as we look to do a sentiment analysis.
Analyzing the Sentiments of the Comments
I've been in circles where sentiment analysis is a bit of a punchline just because, at times, its accuracy is dubious. Still, as an exercise, we will loop through each of the comments and give each a sentiment score. I used two different algorithms; a regular sentiment analysis function provided by TextBlob package, and a sentiment_vader algorithm, one apparently specially tailored for social media and online speak.
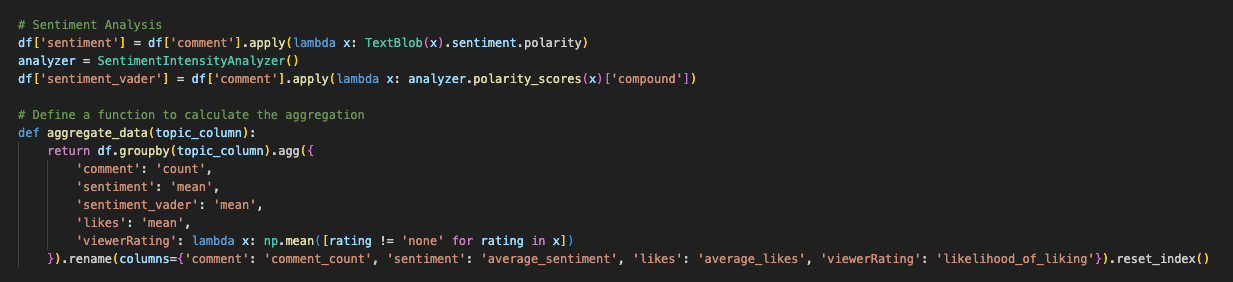
Those scores are attached to the same dataframe we've been keeping track of, the one where we recently assigned three different topic numbers. We simply need to apply the sentiment and sentiment_vader scores, alongside renaming some of the comments, to get our wanted output.
This dataframe will be exported as a CSV, which means, at the end of this script, we will have the screenshot I shared above: a comment, three assigned topic numbers (one for each method), and a sentiment score.
Thanks for reading!